Wykrywanie anomalii z wykorzystaniem autoenkoderów
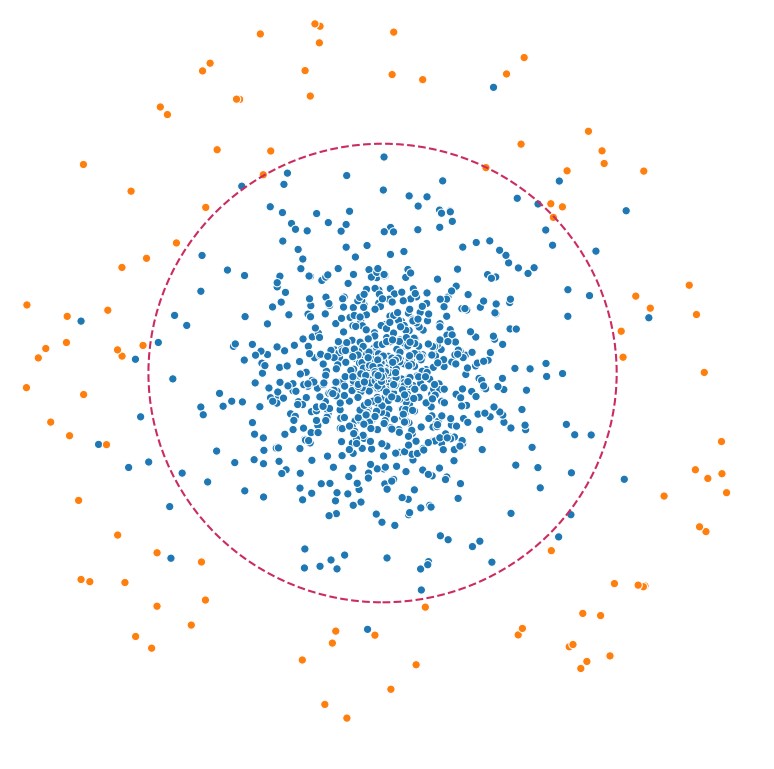
Anomalie w systemach zdarzają się rzadko. Na straży “biznesowej poprawności” stoją warstwy walidacji, które patrząc na parametry zdarzeń, są w stanie wyciągnąć je z procesu. Żądanie wypłaty gotówki w niestandardowym dla właściciela karty miejscu, czy odczyt z sensora przekraczający normy można weryfikować bazując na profilach, czy danych historycznych. Co jeśli jednak zdarzenie na pierwszy rzut oka nie odbiega tak bardzo od normy?
Wielowymiarowa natura danych
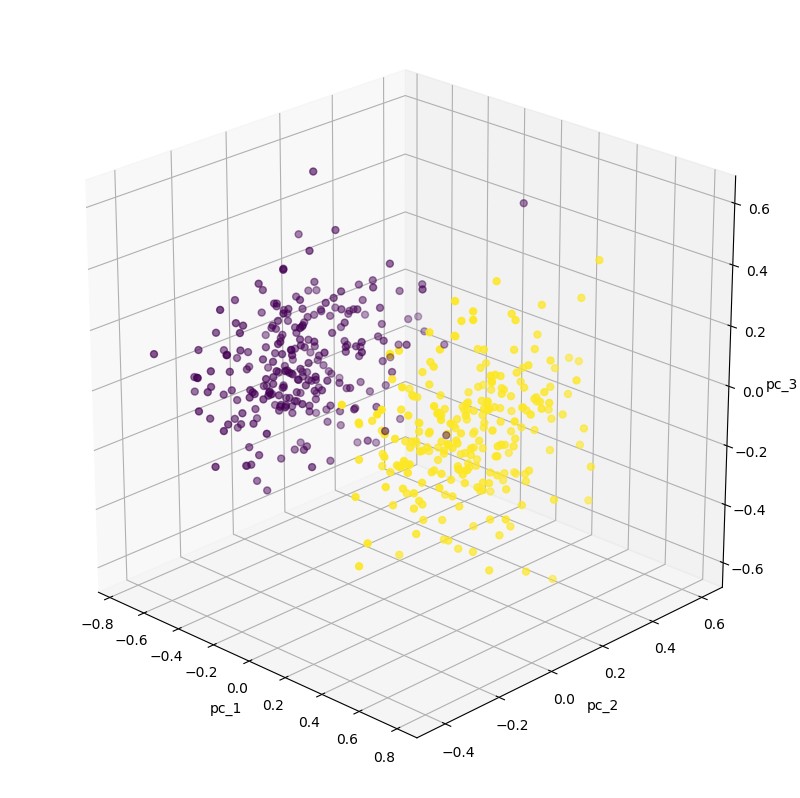
Anomalie nie są łatwe do wykrycia. Często wartości przyjętych cech subtelnie odbiegają od prawidłowego rozkładu, a czasem ich odchylenie od normy jest zauważalne dopiero przy uwzględnieniu serii zdarzeń i charakterystyk czasowych. W takich przypadkach standardowym podejściem jest analiza cech pod kątem np. ich wzajemnej korelacji. Bardzo fajnie do tego problemu podszedł Mirek Mamczur w swoim wpisie.
Na nasze potrzeby wygenerujemy sztuczny zbiór danych, gdzie jedną z klas uznamy za anomalie. Zdarzenia będą posiadały 15 cech, które skupione zostaną dosyć blisko siebie z odchyleniem standardowym na poziomie 1.75.
By zmusić model do większego wysiłku możemy wymusić generowanie danych bliżej, zmniejszając [center_box].
Autoenkoder (undercomplete)
Ciekawą cechą tej architektury jest jej umiejętność zakodowania danych na ich reprezentacje z mniejszą liczbą cech (latent representation). W trakcie nauki miarą wiernego odtworzenia danych wejściowych jest błąd rekonstrukcji.
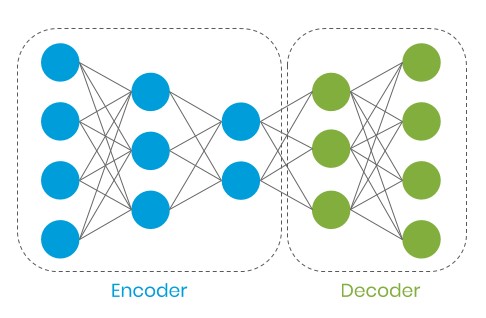
Idąc tym tropem, gdy do nauki modelu przyjmiemy prawidłowe zdarzenia w naszym systemie, model powinien wyciągnąć z nich cechy i na ich bazie odtworzyć zdarzenie z pewnym przybliżeniem. Gdy do modelu trafi zdarzenie anormalne, błąd rekonstrukcji powinien być zauważalnie większy ze względu na inną charakterystykę danych.
Keras
Przy pomocy Pandas’a budujemy DataFrame zawierający dane testowe. Po przeskalowaniu 20% z nich przeznaczonych zostanie na walidacje.
W przypadku niektórych modeli i problemów, które rozwiązują, (np. klasyfikacja z wykorzystaniem CNN) zwiększenie głębokości może pomóc wydobyć z danych większą ilość informacji. Zbyt głębokie Autoencodery nauczą się kopiować X w Y bez zbudowania ich skompresowanej reprezentacji, na której nam zależy. Warto na tym przykładzie sprawdzić, jak będzie się zmieniał MSE, gdy zwiększymy głębokość oraz gdy zredukujemy liczbę neuronów.
Model został przetrenowany na 100 epokach. Powyżej tej wartości nie wykazywał tendencji do poprawy i wynik ustabilizował się na poziomie
0.017–0.018 MSE.
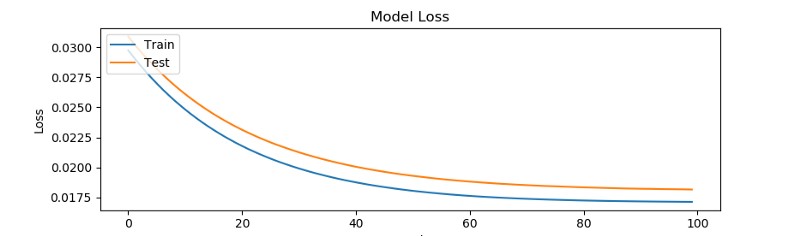
Na wykres naniesiemy próg odcięcia [threshold=0.035] powyżej którego będziemy klasyfikować zdarzenia jako podejrzane.
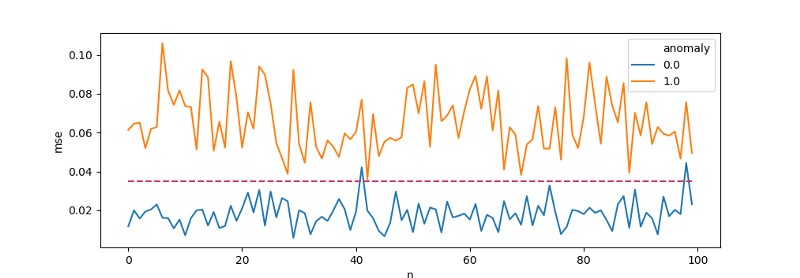
Taki kawałek kodu po modyfikacjach może zostać wpięty do systemu i służyć jako walidator. Wszystko z MSE ≥threshold poleci na dedykowaną kolejkę podejrzanych zdarzeń wymagających analizy, reszta będzie obsługiwaną standardowym flow.
Podsumowanie
W przykładach wykorzystałem sztucznie wygenerowany zbiór danych przeznaczony do klasteryzacji. Dane dla dwóch klas posiadały cechy z zauważalnym rozrzutem między sobą, co pomagało modelowi w trakcie nauki wykryć różnice w Wrealnych sytuacjach tylko niektóre z cech będą odbiegać od normy. Autoenkodery są jedną z możliwości oceny zdarzenia i powinniśmy stosować je razem z innymi algorytmami.
Materiały
- Deeplearningbook [Ian Goodfellow, Yoshua Bengio, Aaron Courville]
- Building Autoencoders in Keras [Francois Chollet]
Mateusz Frączek, R&D Division Leader