DL4J i Kafka Streams w wykrywaniu anomalii
W poprzednim wpisie poruszyłem temat autoenkoderów. Warto wdrożyć tę wiedzę w życie. Wyobraźmy sobie system, gdzie komunikacja między serwisami odbywa się za pomocą Kafki. W trakcie życia systemu okazało się, że niektóre z tych zdarzeń są całkiem szkodliwe. Musimy je wykryć i przerzucić na osobny proces, gdzie zostaną dokładnie zbadane.
Wyjdźmy od paru założeń:
- Mamy 3 topiki
[all_events] z którego spływają wszystkie zdarzenia,
[normal_events] na który przekierujemy poprawne i
[anomalous_events] gdzie wyślemy podejrzane przypadki. - Konsumenci nasłuchujący na [normal_events] i [anomalous_events] są w stanie obsłużyć duplikaty.
- Zdarzenia będziemy przetwarzać w paczkach. Załóżmy 5 sekundowe okno, w którym będziemy agregować wszystko co spłynie z [all_events].
Taką paczkę zdarzeń przekażemy do autoenkodera. - Projekt prowadzony jest w Javie i pozostajemy w skojarzonym stosie technologicznym.
Przetwarzanie zdarzeń z Kafka Streams
Kafka Streams jest biblioteką pozwalająca na przetwarzanie danych pomiędzy topikami. Pierwszym krokiem jest wpięcie się do [all_events] i zbudowanie topologi procesu.
- .groupByKey(…) : Droga do otwarciaKGroupedStream’a, grupujemy po kluczu rekordu.
- .windowedBy(…) : Definicja okna, które przez 5 sekund będzie oczekiwać na zdarzenia. Budując agregacje warto przemyśleć czy problem spóźnionych zdarzeń jest dla nas istotny, najpewniej gdyby nasz model polegał również na charakterystykach czasowych nie chcielibyśmy zgubić zdarzeń dla danego okna.
- .aggregate(…) : Zdarzenia wpadające w trakcie otwartego okna są przechowywane w jednym obiekcie, opakowanie na listę zdarzeń.
- .toStream(…) : Kafka może operować na tabelach (taki charakter mają nasze agregacje) oraz na strumieniach. Na potrzeby dalszego procesowania przechodzimy na strumień.
- .transformValues(…) : Serce całego zamieszania, w tym kroku zebrane zdarzenia zostaną przekazane do modelu. Argumentem jest EventsAggregate, a wynikiem transformacja lista zdarzeń z przypisaną etykietą [NORMAL/ANOMALOUS].
- .flatMap(…) : Zbudowany w trakcie agregacji klucz nie jest już potrzebny. Wynikiem transformacji jest pełnoprawny rekord z oryginalnym zdarzeniem i etykietą jako kluczem.
Filtrując po kluczu, zdarzenia kierowane są na dedykowane topiki, gdzie zostaną odpowiednio obsłużone.
Autoenkoder w DL4J
Biblioteka pozwala na wykorzystanie gotowych modeli zbudowanych w Kerasie. Jest to fajne rozwiązanie, gdy zespół AI pracuje w TF/Keras i on odpowiada za budowę i dostosowywanie modeli. W tym przypadku pójdziemy inną drogą, stworzymy i wytrenujemy autoenkoder w Javie.
Zdarzenia mają analogiczną budowę i wartości, jak w przykładzie z poprzedniego wpisu. Podzielone zostały na dwa pliki CSV [normal_raw_events.csv] oraz [anomalous_raw_events.csv]
Przychodzące dane są nieznormalizowane. Budujemy dedykowany NormalizerMinMaxScaler, który przeskaluje wartości do zakresu [0.0-1.0].
Wytrenowany normalizer posłuży jako pre-procesor dla dedykowanego iteratora, który porusza się po pliku [normal_raw_events.csv].
Autoenkoder będzie posiadał analogiczną budowę jak przywołany przykład w Kerasie.
Model i normalizer zostaje zapisany. Docelowo powinny znaleźć się na dedykowanym zasobie, z którego działająca aplikacja pobrałaby i zbudowała swoją konfiguracje.
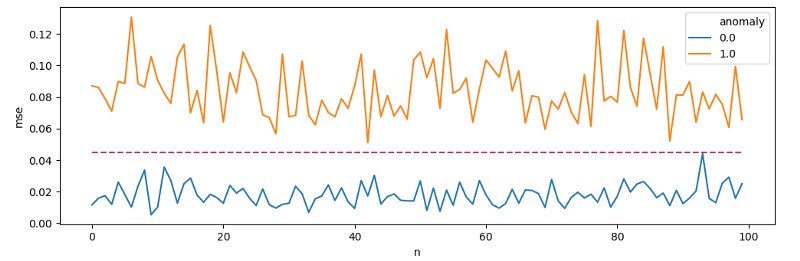
Wytrenowany model może wykazać się średnim błędem rekonstrukcjidla typowych zdarzeń na poziomie 0.0188, natomiast dla anomalii na poziomie 0.0834. Rzucając MSE dla 100 zdarzeń z dwóch grup na wykres, możemy określić próg odcięcia na poziomie [threshold=0.045].
Kafka Stream Autoenkoder Transformer
By zapiąć model w topologie procesu wykorzystam interfejs ValueTransformer zaimplementowany w klasie AnomalyDetection. W konstruktorze powołujemy do życia model wraz z normalizerem oraz klasy pomocne w obliczeniu błędu rekonstrukcji.
Metoda transform otrzymuje zebrane w oknie zdarzenia. Muszą zostać one zmapowane na format zrozumiały dla modelu [INDArray]. Dla każdego ze zdarzeń obliczany jest błąd rekonstrukcji. Te, które przekroczą próg otrzymują klucz ANOMALOUS.
Podsumowanie
- W założeniach przyjęliśmy, że konsumenci zdarzeń potrafią obsłużyć duplikaty. Jest to bezpieczna praktyka, ale wyobrażam sobie sytuacje gdzie będzie to trudne do zrealizowania. Warto wtedy rozważyć wykorzystanie metody .suppress(…).
- Okna będą buforowane i wynik nie zostanie przekazany w dół procesu po 5 sekundach. Zauważymy raczej spływanie agregatów w paczkach co 30 sekund. Dla testów możemy modyfikować parametry takie jak [CACHE_MAX_BYTES_BUFFERING_CONFIG] czy [COMMIT_INTERVAL_MS_CONFIG]by spróbować uzyskać krótsze czasy.
- Przy wyborze technologi warto rozważyć takie aspekty jak klasteryzacja, koszt wdrożenia oraz dostępne metody integracji. Możliwe, że Spark czy Flink będzie lepszym rozwiązaniem.
Materiały
Mateusz Frączek, R&D Division Leader